An idea
How can we detect the presence of a brand image on a webpage?
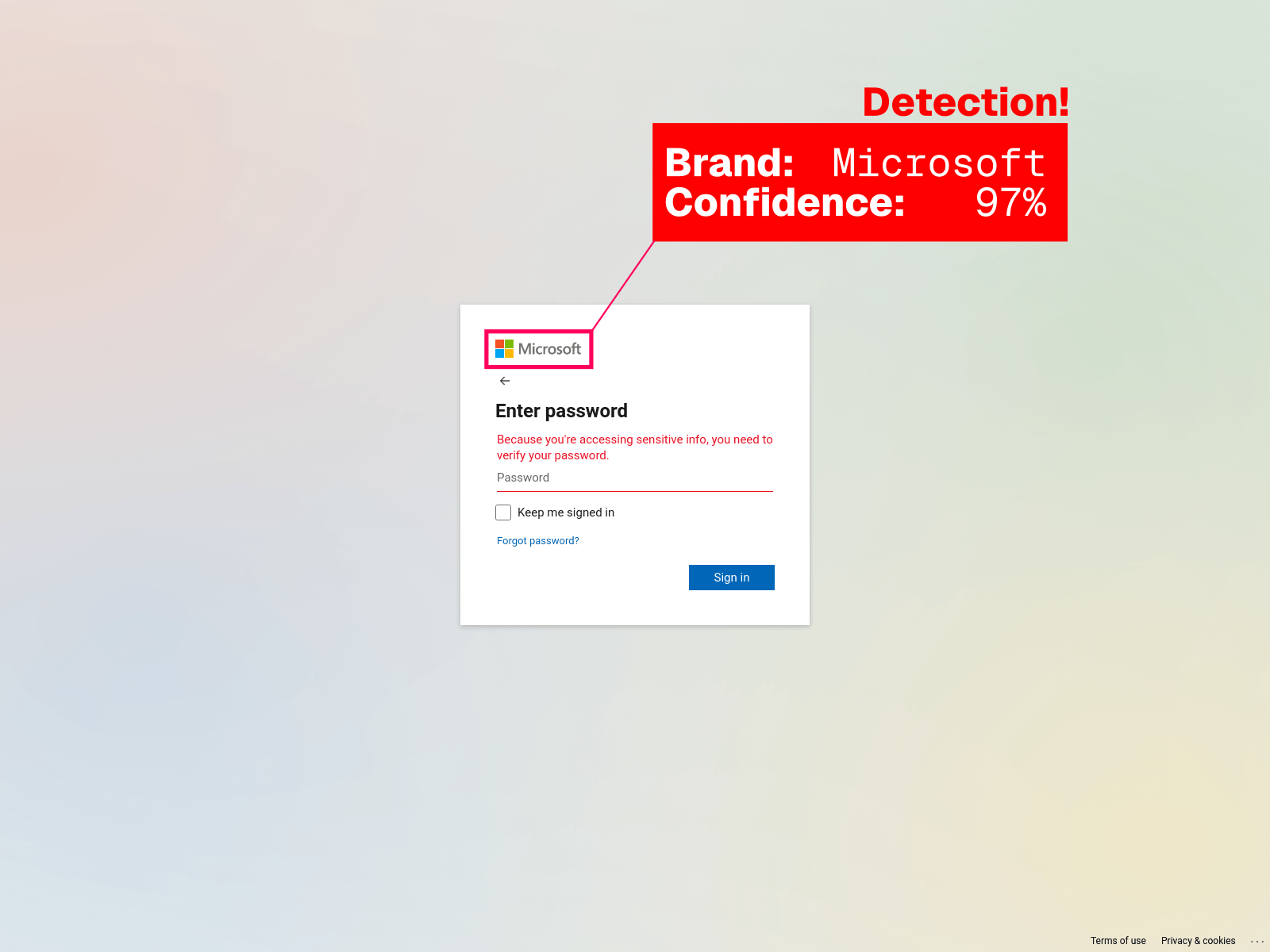
This specific use case is from my project, Webhood, a self-hosted URL scanning platform designed to analyze websites for potential phishing threats. Phishing is a common tactic where attackers lure victims to fake websites with the goal of stealing sensitive information, such as login credentials or personal data. These phishing sites can mimic legitimate websites, often impersonating the login pages of well-known brands like Microsoft. Recently, especially since the pandemic, attackers have used fake websites that trick users into paying for "unexpected shipping costs" by imitating reputable shipping companies like UPS or DHL.
To establish trust with users, attackers frequently use logos of trusted brands on their phishing sites. For example, a large DHL logo on a non-DHL website is a clear red flag. While identifying the true nature of the site (whether it is actually DHL or not) is a complete challenge left my project, presence of such logos can help flag the site as suspicious.
Digging deeper
Given a website, the most straightforward approach might be to extract all images and compare them against a database of logos (and possibly other brand-related images) that we want to detect.
However, after further iterations, I determined that extracting all images is not at all necessary. To reduce noise, we would need to filter out images that are not visible on the page, detect logos embedded within other images, and assess how prominently the images are displayed to the user. Simply scraping the website is not sufficient; instead, we must emulate a user's experience by visiting the website with a browser.
The solution
With the additional insights, analyzing a screenshot of the webpage is sufficient for our needs. Since we already have the technology to capture screenshots—including tools that can bypass CAPTCHAs, handle slow website loads, overcome geographic restrictions, and simulate a live user experience (hint) gathering test data becomes straightforward.
For object detection within images, there are several excellent computer vision methods available, with YOLO being a popular choice. I selected YOLOv8 for this task, as it is particularly well-suited for object detection. While YOLOv8 can also do real-time detection—something we don't specifically require for this prototype—it may very well be a bit overkill for this project. However, the model is well-documented and lightweight enough to run locally, making it a practical choice for our needs.
Note: YOLOv8 is the name of the latest model by Ultralytics at the time creating this prototype (August 2024). However, YOLO (short for you-only-look-once) is the name of the algorithm introduced by Joseph Redmon et al. in 2015. There are other models carrying the same YOLO name but these different versions may be created and owned by different entities. Ultralytics' version are somewhat restrictive license-wise and is not used as part of my upcoming Webhood features as this would possibly be against their licensing terms.
Training the model
To train the model, we need to:
-
Gather brand images: For this prototype, we begin by manually collecting a selection of logos, starting with Microsoft.
-
Generate variations of the images: To better simulate real-world usage of logos on phishing websites, we create different versions of each logo. This includes varying sizes, converting them to black and white, and introducing minor distortions like tilting the logos.
-
Capture screenshots of websites: We then gather screenshots from a wide range of websites, ideally those that do not contain the logos we are tracking. For this step, I used lists of popular websites and fed the URLs into Webhood to collect approximately 20,000 unique screenshots.
-
Create training and test data: Next, we generate training and test datasets by randomly inserting the logo variations into the collected screenshots. As we generate this data, we also record the exact locations of the logos within each image.
 Example of the test data. A Microsoft logo is inserted into a screenshot of a random website.
Example of the test data. A Microsoft logo is inserted into a screenshot of a random website.
 Another example of the test data with different sized logo. Can you spot the logo?
Another example of the test data with different sized logo. Can you spot the logo?
Results
After training the model, we can use the model to perform object detection on a real-world screenshot which yields the following results:
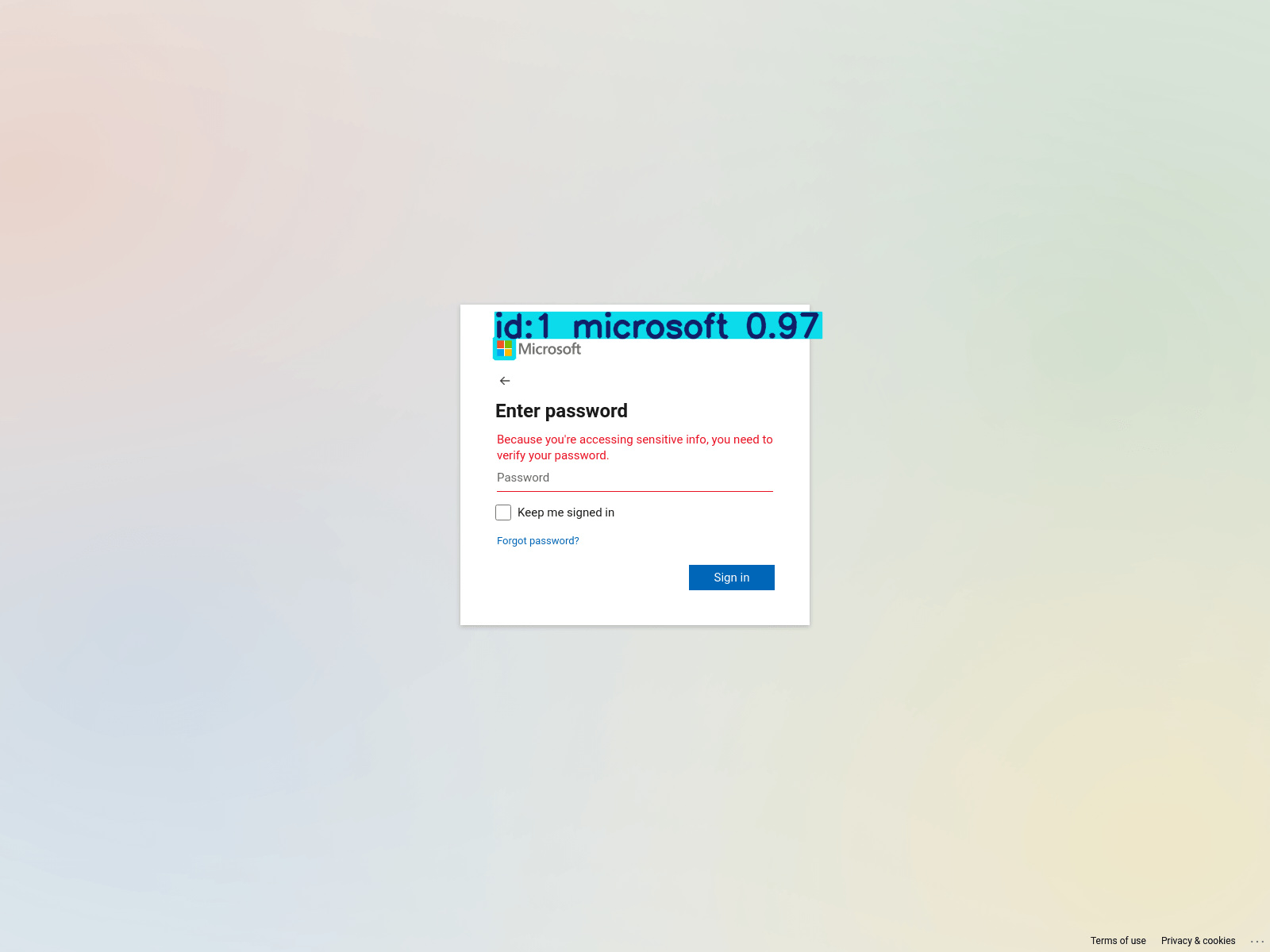 Example of the real data.
Example of the real data.
As shown in the example, the model successfully detects a Microsoft logo on a login page that closely resembles Microsoft's official login page. Upon analysis, I identified this as likely a phishing site, possibly at a stage of being prepared for deployment. The blue overlay displaying Microsoft: 0.97 indicates that the model has 97% confidence in matching the logo to the Microsoft label we defined during the training.
Here are few more examples:
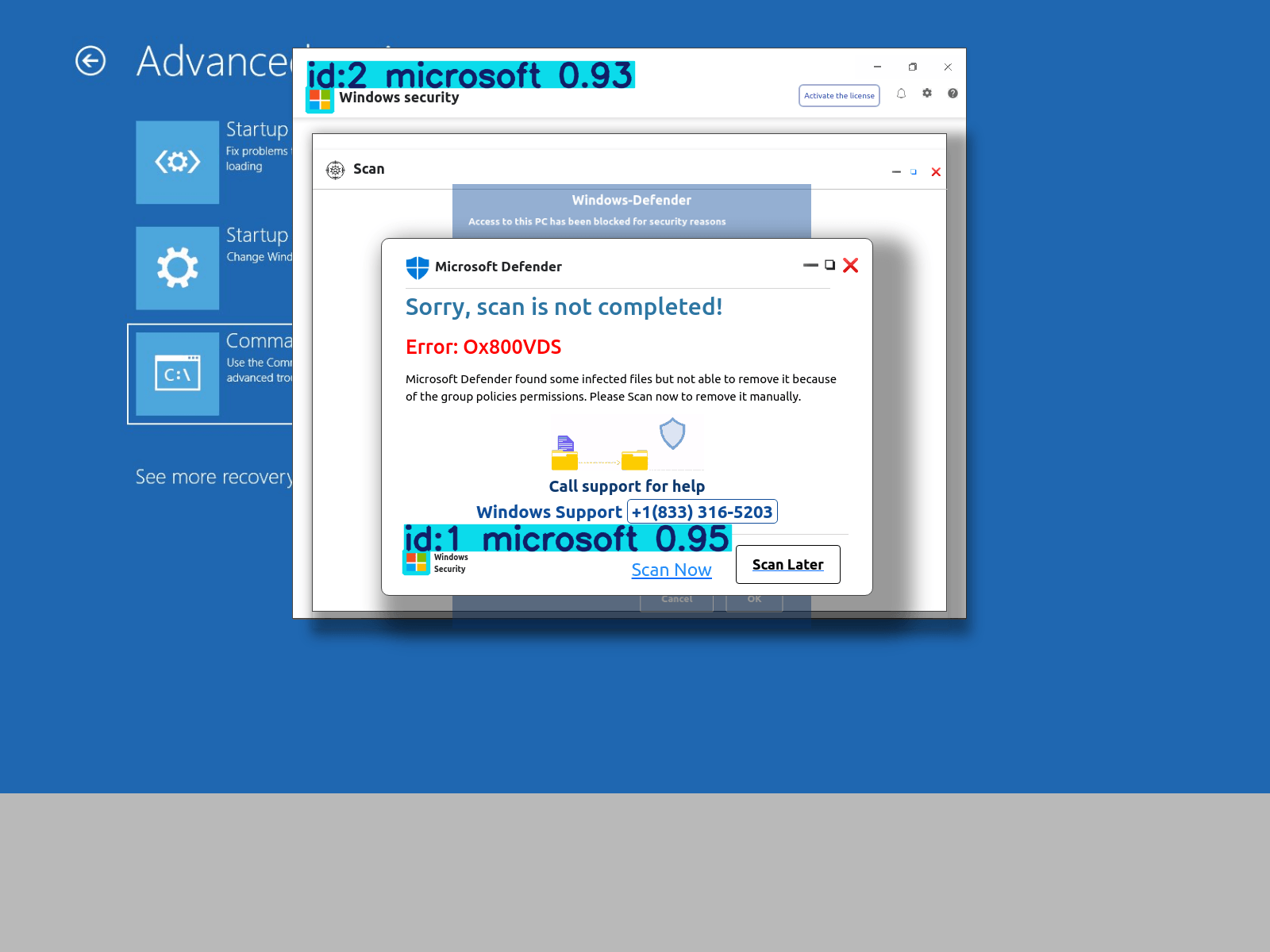 Another example of a detection of a real phishing site.
Another example of a detection of a real phishing site.
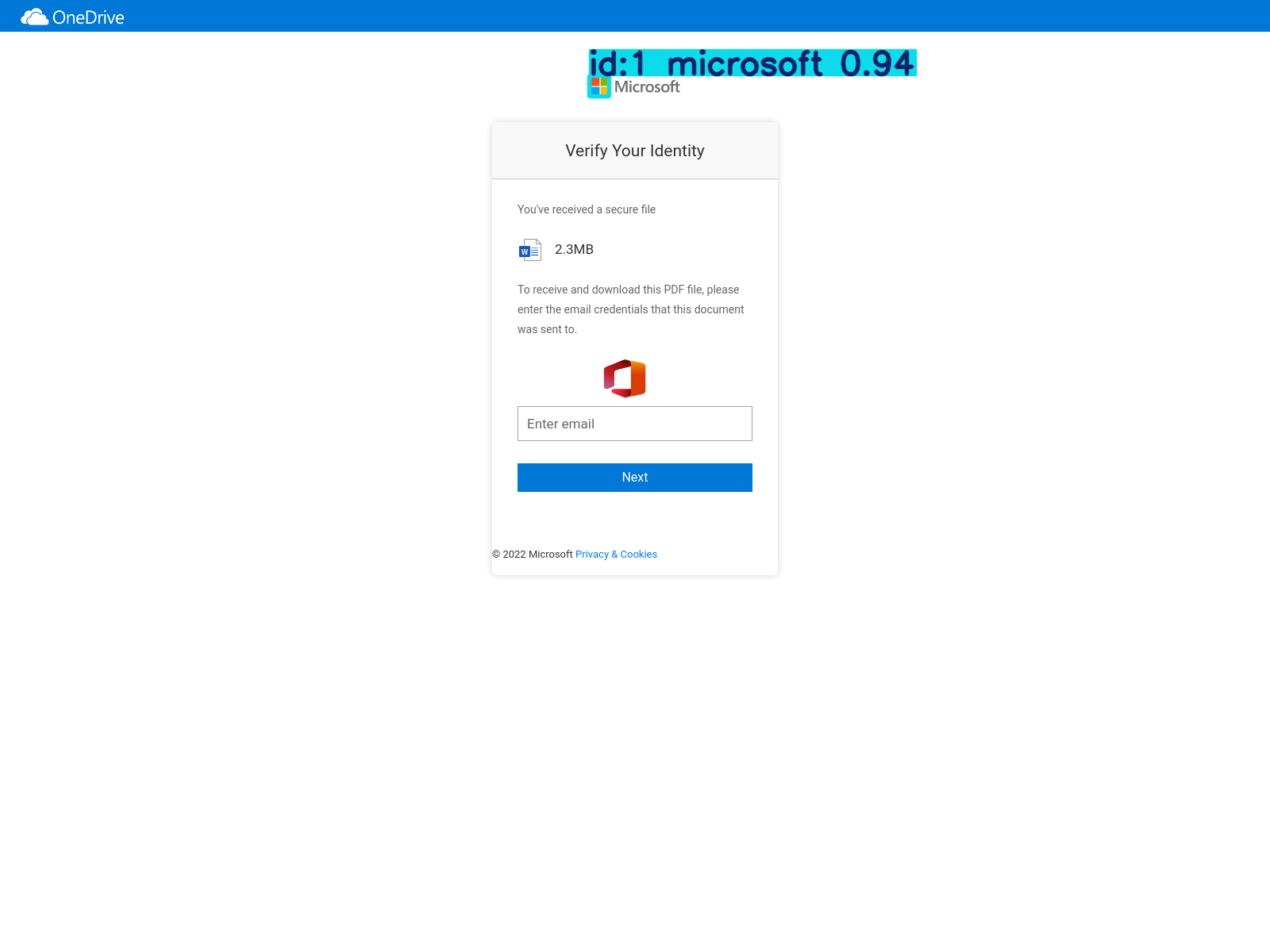 Yet another example of a detection of a real phishing site.
Yet another example of a detection of a real phishing site.
Interestingly, the model is also able to detect logos that are well embedded into a background and even slightly transformed as seen in the following example:
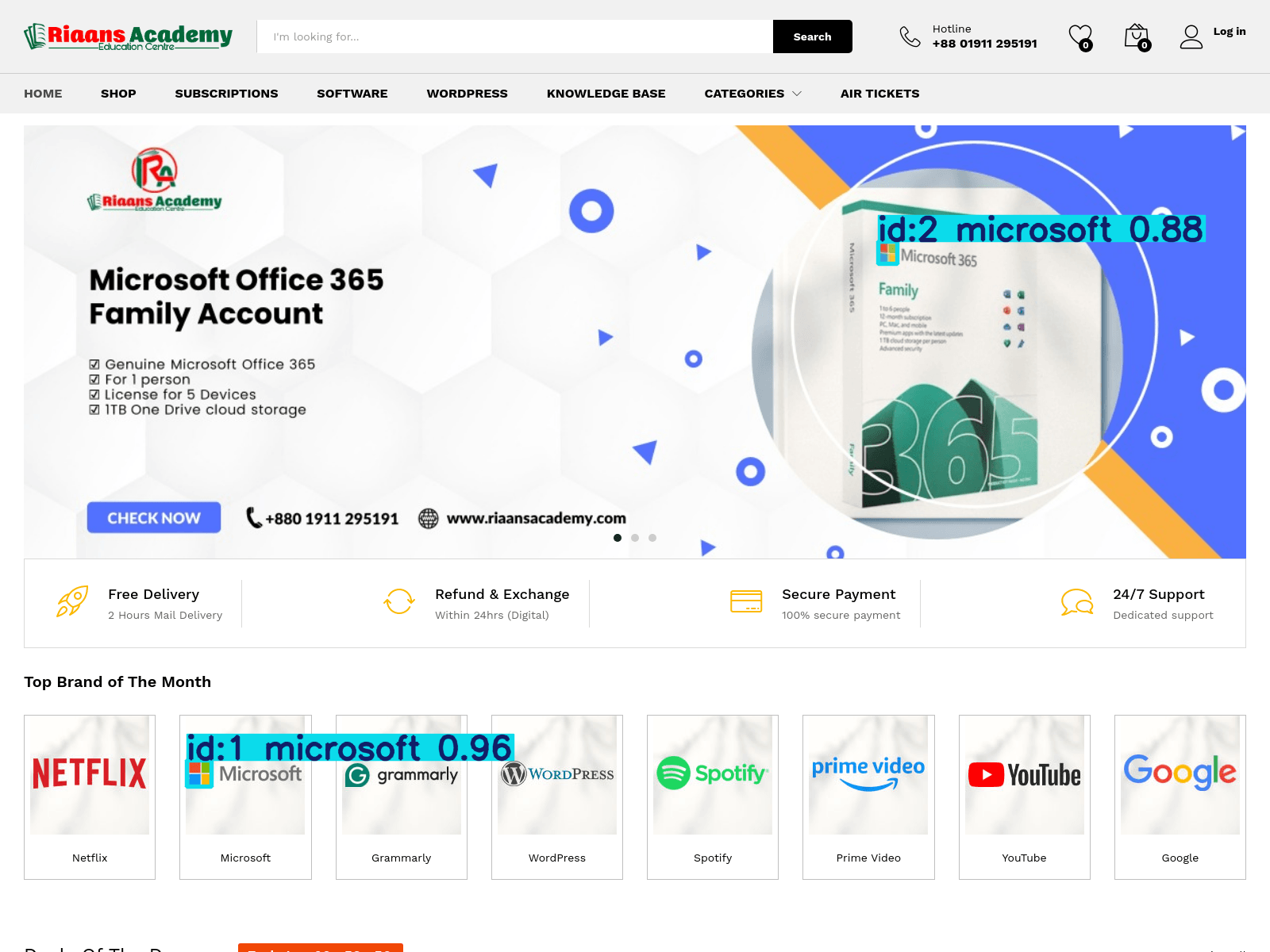
Beyond the prototype
As seen in the last example, although the model is able to detect the Microsoft logo, the site does not appear to be a phishing site. Detecting the presence of a brands logo is only one of the steps in identifying phishing sites. The next steps would be to analyze the content of the site, the URL, and other factors to determine if the site is indeed a phishing site.
To be able to reliably detect the presence of a brand's image on a website presents potential challenges when using the approach described above. Some of these challenges include:
- Number of brands: Although there are no hard limits on how many classes the model can be trained on, the performance of the model may degrade as the number of classes increases. Training a model on one brand image is relatively simple, but training on hundreds or thousands of brands would require significantly more data and computational resources. Ultimately this may require training and use of multiple models for optimal performance.
- Multiple logos: The model would need to be able to detect multiple logos on a single page. This is possible for example with YOLOv8, but, again the performance may be limited when coming across a site with multiple brands.
The model will also always suffer from false positives and false negatives. The model may detect a logo that is not present or fail to detect a logo that is present. Although the false positive rate can be adjusted by changing how confident we want the results to be, preventing false negatives is significantly more difficult task.
Here is an example of a false positive:
